Understanding DNS: A Comprehensive Technical Overview
Table of Contents
As promised in my last article, I will show you the technical aspect of passive information gathering/recon. However, I don’t want to rush and simply brush over topics that are as important as DNS for instance, which is our topic of the day. I want to dive into its inner workings and explore all it has to offer since it’s the starting point into mapping out an attack surface because it reveals subdomains, IPs and other infra details. You can’t look into something you haven’t found, can you?
I will make this a multipart series so that we have the time to truly cover all the aspects of our subjects. I felt that DNS deserved its own article, but the next one will probably cover more topics, like the application itself and all its moving parts for instance.
What is DNS fundamentally?
We’ll start the article at a high level, and dive deeper as we go by building on top of our foundation. Keeping with the input -> system -> output[¹] theme, we’ll think of DNS as a black box for now. What we have to figure out first, is what it takes (input), and what the system gives back after it’s done (output).
A way to address those two points is to see DNS as a system that takes human-friendly computer hostnames (often referred to as domain names), and converts them to IP addresses.

Keep this reference point in mind as we explore the details—it’ll help you stay grounded and avoid unnecessary confusion.
Why do we need DNS?
I’d like to go on a brief tangent about why we use DNS. Similarly to a compiler, its main purpose is to help humans interact with their machines. In the way that it allows us to input something that is easy for us to understand, and translate it to something that is easy for the machine to understand. I’m sure you can imagine that, it’s practically impossible (or very difficult) to remember the IP addresses of all the internet services we use. And machines don’t understand anything other than said IP addresses. So we bridge the gap by using DNS, because it handles that job for us.
Abstraction
Although domain name to IP translation is the primary purpose of DNS, it helps us in many other ways. For instance, it abstracts away the underlying infrastructure by always pointing to entities’ machines. Say a company migrates their servers to a different hosting provider for example. You’d still use the same example.com domain, whether their address is 104.218.63.175 or 23.154.89.126 because they would make sure that their domain name always points to it. You can think of it as pattern-matching, here’s a code snippet to illustrate this (omitting the actual resolution, we cover this later in the article):
use std::net::Ipv4Addr;
enum HostingProvider {
Epik,
AWS,
}
fn get_server_ip(domain_name: &str, hosting_provider: HostingProvider) -> (String, Ipv4Addr) {
let ip_address = match hosting_provider {
HostingProvider::Epik => Ipv4Addr::new(104, 218, 63, 175),
HostingProvider::AWS => Ipv4Addr::new(23, 154, 89, 126)
};
(domain_name.to_string(), ip_address)
}
fn main() {
let domain_name = "example.com";
let (domain, ip1) = get_server_ip(domain_name, HostingProvider::Epik);
println!("{} points to {}", domain, ip1);
let (domain, ip2) = get_server_ip(domain_name, HostingProvider::AWS);
println!("{} points to {}", domain, ip2);
}This practice can be done manually by handling what we call DNS records yourself, or automatically through the use of Dynamic DNS. But let’s not get carried away here.
Load balancing and scalability
Another way DNS proves to be useful is by helping servers manage load. Instead of relying on a single server to hold all the records in the world—DNS distributes the workload across multiple servers. With this design, we can assign different roles to each server and ensure kreeezi scalability!
How does DNS work?
Now that we understand the core of DNS, we can explore its hierarchical and distributed nature. And start looking into how it actually works, from the original query on your device, to a response.
A hierarchical and distributed nature
Like I’ve mentioned before DNS is a hierarchical system, which means that every server or resolver has a specific role in the process of resolving a query. And it’s distributed because at every step of this resolution, a different server could potentially be used to continue the process. So what does a typical resolution process look like?
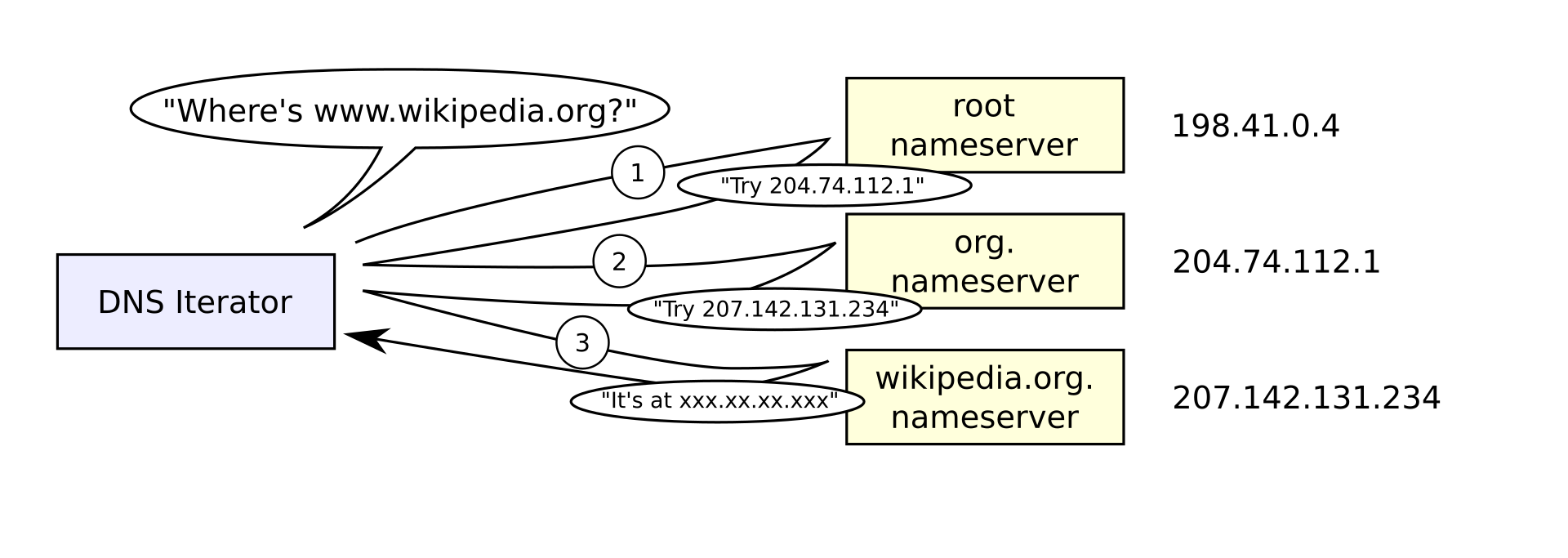
As you can see in this image, we have four DNS servers. But we’re actually going to take a step back for a second, because we first have to understand what happens before even getting to the DNS iterator. Which we’ll get into shortly.
The Resolution Process
When you send a DNS query from your device (like google.com), it first goes to its resolver. The distinction between a server and resolver is very important to make. Because you have to understand that you most likely don’t have a DNS server on your device. What you have is called a resolver, and its main function is to do exactly that, resolve DNS queries. In layman’s terms this would mean: find and respond with the IP of a corresponding domain name.
Your devices’ resolver (which is called a stub resolver) primarily does this by looking through its cache. That’s where it saves successful resolutions for future use. But what happens when we can’t find the record in the cache?
This is where we get into its distributed nature, which is something fundamental that you must grasp before moving forward. Every time a DNS resolver doesn’t have the answer to a query, it goes to the next server in the hierarchy. So in the case of your devices resolver, it would then ask your router for a response (going to the router is not default behavior, but a default in most devices network configurations).
Your router has what’s called a forwarding resolver or non-recursive resolver. It works very similarly to the devices stub resolver with the main differences being that it’s way more configurable and can have multiple upstream servers as opposed to one. So if it still can’t find an answer here it will forward the query to your ISPs DNS server. This is where it gets interesting, and what figure 2 is illustrating.
DNS Iterators and Authority
Here, we’ll encounter what’s called a dns iterator (also called recursive resolver). I like to think of it as the starter of a Q&A session. Because as you can see in figure 2 it starts by asking a root nameserver for an answer, and goes through that whole chain until we find it. Let’s explore how that plays out in practice.
But first we have to introduce a new concept called authority. As you can see in figure two there are three servers in this image that are categorized as nameservers, this differentiates them from dns servers like your routers for example because they are authoritative over a given zone. Which means they hold records and are the source of truth for them.
Understanding Zone Authority
So we have:
- Root zone authority
- TLD zone authority
- Domain zone authority
As we’ve covered before, DNS servers will only give you an answer when they have it. So in our little Q&A session the root server would say “I don’t have google.com, I only know where you can find a server which has all the .com records i.e. a TLD zone authority” and point us to that. We’d then go to the TLD zone authority, ask it for google.com, and it’d say “I don’t have google.com, I only know where you can find a server which has all the google.com records i.e. a Domain zone authority” and point us to that. We’d then go to the Domain zone authority to get our final authoritative answer.
One little thing I would like to clear up, because it was a common point of confusion for me is that I wondered “but what about subdomains?” these are all covered by the domain zone authority, full-stop. So if that was a question you were asking yourself, just know that the process doesn’t go any further.
That pretty much covers it all, you now have a good understanding of the inner-workings of the Domain Name System. If you’d like to learn how to implement one yourself or hack DNS, I invite you to consult any of the following sections: A programmer’s perspective, A hacker’s perspective (will be an article, I’m working on it!!).
Otherwise, I hope you had a good read, and I’ll see you in the next one!
A programmer’s perspective
As a practical complement to this article I made my own DNS server, so I’d like to do a brief, high-level overview of how to implement it. For the more experienced programmers among us, all the information I’ve provided above is probably enough to figure it out with a bit of documentation[²][³]. But this can serve as both a learning opportunity for novices and a refresher for the rest. We will see how it all ties back to cybersecurity and finding/developing exploits at the end of the article. (not true! I’m working on a separate article for it)
When you really think about it, making a basic DNS is simple. It’s all about setting up a socket, receiving a string and parsing through it to build a response, then serialize the response and send it back to the client. So our first order of business is to implement our communication interface, because all networked programs need a mutually agreed-upon “place” to do so.
Sockets
A simple way to think of sockets is that it’s a place where two programs/processes agree to meet at to communicate. As illustrated by this image, you can see that two tiny people are vibing right in there. Because that’s the purpose of sockets, they’re comfy endpoints for apps & processes to send and receive data through. And just like in a human conversation, both client and server can talk at the same time since sockets are full-duplex! Contrary to traditional client-server models.

Knowing where the data flows is crucial to know when implementing a system. It’ll also do us good when we start looking at security implications and how DNS could be hacked on ;)
Socket type considerations
Traditionally, DNS has mostly relied on UDP for its speed and efficiency, but it’s been changing in recent years due to new technological requirements and security considerations. While you could theoretically use any type, UDP and TCP make the most sense and allow for all of its features to flourish. You can find more information about both of these and more in IBM documentation
Raw bytes as queries/responses
Responses and queries are typically sent as raw bytes and then deserialized inside our programs to parse through the message data. We’ll look at them as hex values to simplify here. The query message structure is usually presented with an image such as this one:
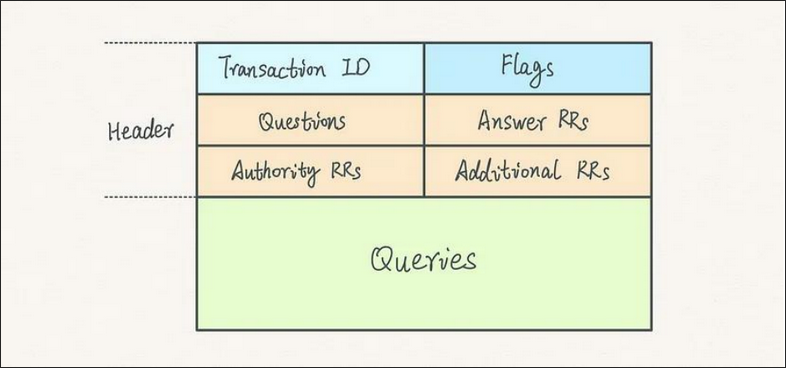
However, that visualization has never worked for me. So for those of us who prefer the string representation, here it is already broken down :)
9620 1000 0010 0000 0000 0000 08 70696e646a6f7566 03 7a7978 00 0001 0001
DNS Queries
Keeping with our example up above, we’ll deconstruct what all this data really means! DNS messages are comprised of several categories with the most notable ones being covered in Figure 4. In our header section all categories are 2 bytes long, which makes the whole section 12 bytes since it has 6 of them. Here’s the header of our example query
- ID:
9620 - Flags:
1000 - Question count:
0010 - Answer count:
0000 - Authority count:
0000 - Additional count:
0000
And its corresponding Question! aka the actual domain name and the question type/class!
We can’t put a pre-defined size on this since the labels are of dynamic size (although they’re restricted to 63 bytes)
- Labels (length, value):
08 70696e646a6f7566 03 7a7978try to guess this domain name ;) - Zero byte terminator:
00 - Question type:
0001(A, AAAA, etc…) - Question class:
0001(IN, CH, etc…)
As you can see most of the counters are at 0 because this is only the first part of the “conversation” so no responses have been received yet, thus causing these low counts. The flags can actually be broken down way more, and as for the ID it just serves as an identifier so nothing worth noting happens to it. There are many articles covering these details, and more depth than we would ever have the time to get into here so I invite you to look at official sources like the ones mentioned in the endnotes.
DNS Responses
The response message follows a similar structure but includes our answer. Let’s look at our example:
9620 8180 0001 0001 0000 0001 08 70696e646a6f7566 03 7a7978 00 0001 0001 c00c 0001 0001 00000e10 0004 0a0a0a0a
The header has the same categories but with the response bit set and counts updated to reflect included answers. The question section is preserved, and we get the additional our answer section!
- Name pointer:
c00c(points back to question name/labels) - Type/Class:
0001 0001(A record, IN) - TTL/Length:
00000e10 0004(3600s, 4 bytes) - Address:
0a0a0a0a(10.10.10.10)
DNS uses compression (that c00c pointer) to avoid repeating the domain name.
Final considerations
If you know how to program you pretty much have everything you need to implement a basic DNS right here. That’s all there is to it. Consult the official sources for guidelines on connection types, message structures etc… and you’re good to go. Of course many features have been built on top of it, but this is the core of DNS.
My implementation mostly focuses on understanding everything I’ve outlined in this section, so I haven’t bothered to work on cache or recursive resolution as they’re optimizations on top of this very basic protocol. I only have zone file parsing as my method of choice for resolution.
Perhaps I could’ve covered that part a bit, but I can guarantee you that I’m far from being an authority on writing lexers. Mine is barely pulling what it needs to from those files, so I kindly suggest you go find another source for help on this!! (perhaps a future article once I’m good!)
Endnotes
I wrote this article as I was learning DNS, so if you’re more knowledgeable about computers than I am, feel free to reach out on X.
Btw, if I were to learn this all over again I’d just use the dig +trace example.com command, and ask an LLM about everything that just popped up on my screen until I understand DNS. That’s probably the quickest way to learn it in my opinion.
Citations:
[1] George Hotz, “what is programming? (noob lessons!),” YouTube, July 31, 2020. [Online video]. Available: https://youtu.be/N2bXEUSAiTI?si=Z9d1Wtpeh8K2ikzK&t=912.
[2] P. Mockapetris, “Domain Names - Concepts and Facilities,” RFC 1034, Internet Engineering Task Force, November 1987. [Online]. Available: https://datatracker.ietf.org/doc/html/rfc1034
[3] P. Mockapetris, “Domain Names - Implementation and Specification,” RFC 1035, Internet Engineering Task Force, November 1987. [Online]. Available: https://datatracker.ietf.org/doc/html/rfc1035